影響を推測する
- 前段
いきなりたとえ話から入る。「筒井康隆と夢野久作の文章は似ている」という命題があったとしよう。それを「証明」する手段についてはここでは立ち入らない。両者の文章を抜書きして並べたり、テキスト化して、単語の使用状況や文章構造などをコンピューターを使って比較したり、いろいろな方法が考えられるが、ともかく仮にこの命題が真であったとする。
次に考えることは何かというなら、何故それが起こったのか、という理由づけである。両者の生年を比べると、筒井が夢野の文章を読んで真似したのだという仮説が考えられる。
夢野→読書体験→筒井
これに対してはそもそも両者は同じように戦前の国語教育を受けていたのだから似た文章を書くのではないかという仮説も考えられる。
国語教育→→夢野
↓
筒井
両者の精神構造が類似しているからだという仮説も考えられる。
精神構造→→夢野
↓
筒井
他にもあるかもしれないが、これで網羅したことにする。次になすべきは、どの仮説がより正しいかの検証である。ここではオッカムの剃刀の原則を用いる「べき」だろう。読書体験という新たなファクターを入れなくても、両者が受けたことが確実である国語教育というファクターで説明がつくし、「精神構造」などというあやふやなファクターを用いる必要はない。つまり、2番目の仮説を正しいものだろうと受け入れることになる。もちろん隠れた交絡因子には常に注意する必要があるし、より「確からしい」説が出てきたなら、それを「正しい」として受け入れるべきだろう。
文献学的な専門トレーニングを受けている訳ではないのであまり自信はないのだが、「影響」を考えるとはこういうことだと思う。
- モデル
影響関係を論じるに当たって使えるモデルにはいくつかのパターンが考えられる。

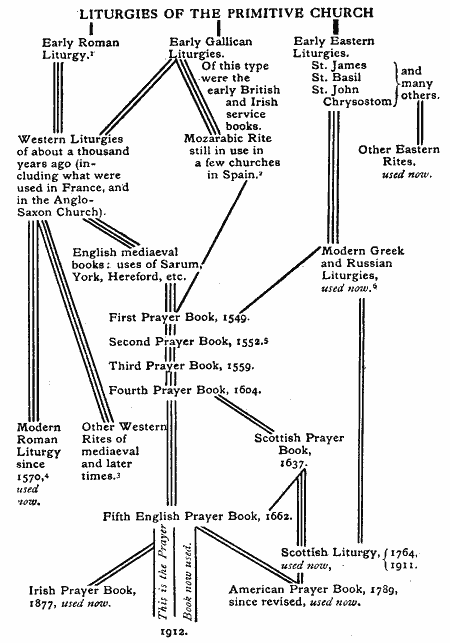
どれをとってもいいが、よりシンプルなものを選ぶべきである。そういう観点からだと、"tree"のモデルが用いられやすい。
しかし、それだけでは説明がつかないケースが出てきたなら、例えば、こういったものやこういったもののようなネットワーク構造をしたモデルを使う必要が出てくる。『文庫版 姑獲鳥の夏 (講談社文庫)』に出てきた姑獲鳥の起源はまさにそういうものだった。
{kind=link}
{kind=link}
- 本論
というわけで、本は読んでいないけど、自分の仮説に使えないデータを完全に無視した『手塚治虫=ストーリーマンガの起源』は酷いんじゃないの、という話でした。
ネタ元サントリー学芸賞is Dead! 手塚治虫=ストーリーマンガの起源が受賞 - AYS:など。